
Veamos el siguiente diagrama para un descripción general de la arquitectura moderna de aplicaciones web:
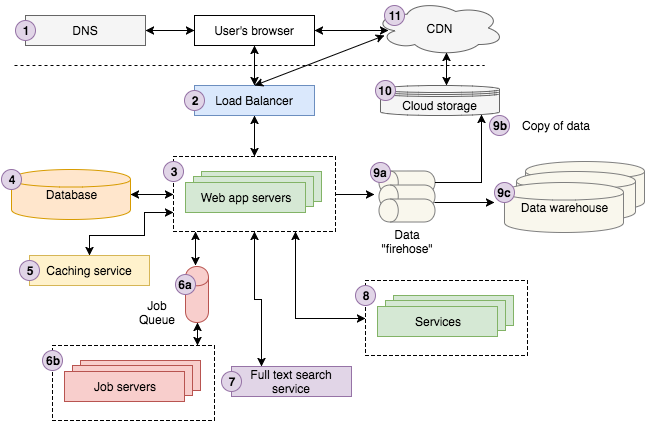
El anterior diagrama es una representación bastante buena de la arquitectura en Storyblocks (Nota del traductor: Storyblocks es la compañía donde trabaja el autor original de este artículo; más datos al fin de este artículo). Si no eres un desarrollador web experimentado, es probable que te resulte complicado. El recorrido a continuación debería hacerlo más accesible antes de sumergirnos en los detalles de cada componente.
Un usuario busca en Google «Fuerte, hermosa niebla y rayos de sol en el bosque». El primer resultado es de Storyblocks, nuestro sitio líder en fotos e imágenes vectoriales. El usuario hace clic en el resultado que redirige su navegador a la página de detalles de la imagen. Por debajo, el navegador del usuario envía una solicitud a un servidor DNS para buscar cómo contactar Storyblocks y luego envía la solicitud.
La solicitud llega a nuestro balanceador de carga, que elige aleatoriamente uno de los aproximadamente diez servidores web que tenemos en funcionamiento al momento de procesar la solicitud. El servidor web busca información sobre la imagen en nuestro servicio de almacenamiento en caché y obtiene los datos restantes de la base de datos. Notamos que el perfil de color para la imagen aún no se ha calculado, por lo que enviamos un trabajo de «perfil de color» a nuestra cola de trabajos, que nuestros servidores de colas procesarán de forma asincrónica, actualizando la base de datos adecuadamente con los resultados.
A continuación, intentamos encontrar fotos similares enviando una solicitud a nuestro servicio de búsqueda de texto completo utilizando el título de la foto como entrada. El usuario está conectado a Storyblocks como miembro, por lo que buscamos la información de su cuenta en nuestro servicio de cuentas de usuarios. Finalmente, enviamos un evento de vista de página a nuestra manguera de incendios, para que se registre en nuestro sistema de almacenamiento en la nube y finalmente se cargue en nuestro almacén de datos, que los analistas usan para ayudar a responder preguntas sobre el negocio.
El servidor ahora representa la vista como HTML y la envía de vuelta al navegador del usuario, pasando primero por el equilibrador de carga. La página contiene activos Javascript y CSS que cargamos en nuestro sistema de almacenamiento en la nube, que está conectado a nuestra CDN, por lo que el navegador del usuario se pone en contacto con la CDN para obtener el contenido. Por último, el navegador visualiza la página para que el usuario la vea.
A continuación, te guiaré a través de cada componente, proporcionando una introducción «101» de cada uno, lo que debería darte un buen modelo mental de la arquitectura web de aquí en adelante.
1. DNS
DNS significa «Sistema de Nombres de Dominio» (de la sigla en inglés de «Domain Name System») y es una tecnología esencial y que hace posible la world wide web. En el nivel más básico, el DNS proporciona una búsqueda de clave/valor desde un nombre de dominio (por ejemplo, google.com) a una dirección IP (por ejemplo, 85.129.83.120), que es necesaria para que tu computador pueda enrutar una solicitud a la dirección apropiada del servidor. Haciendo analogía con los números de teléfono, la diferencia entre un nombre de dominio y una dirección IP es la diferencia entre «llamar a Juan Pérez» y «llamar al 201-867–5309». Del mismo modo en que necesitabas una guía telefónica para buscar el número de Juan en los viejos tiempos, necesitas un DNS para buscar la dirección IP de un dominio. Por lo tanto, puedes pensar en DNS como la guía telefónica de Internet. Hay muchos más detalles que podríamos ver aquí, pero los pasaremos por alto porque no es crítico para nuestra introducción a nivel «101».
2. Balanceador de Carga
Antes de sumergirnos en los detalles sobre el balance de carga, vamos un paso atrás revisar escalabilidad horizontal y vertical de una aplicación. ¿Qué son y cuál es la diferencia? En pocas palabras, en esta publicación de StackOverflow, escalabilidad horizontal significa que es posible crecer agregando más máquinas a su grupo de recursos, mientras que la escalabilidad «vertical» significa que creces agregando más potencia (por ejemplo, CPU, RAM) a una máquina existente.
En el desarrollo web, (casi) siempre vas a querer escalar horizontalmente porque, por decirlo así de simple, las cosas se echan a perder. Los servidores se caen en cualquier momento. Las redes se degradan. Centros de datos completos ocasionalmente quedan fuera de línea. Tener más de un servidor te permite planificar interrupciones para que tu aplicación continúe ejecutándose. En otras palabras, tu aplicación es «tolerante a fallas». En segundo lugar, la escalabilidad horizontal te permite acoplar mínimamente diferentes partes del backend de tu aplicación (servidor web, base de datos, un servicio X, etc.) haciendo que cada una de ellas se ejecute en diferentes servidores. Por último, puedes alcanzar una escala donde ya no es posible escalar verticalmente. No hay computadora en el mundo lo suficientemente grande como para hacer todos los cálculos de tu aplicación. Considera la plataforma de búsqueda de Google como un ejemplo por excelencia, aunque esto se aplica a empresas a escalas mucho menores. Storyblocks, por ejemplo, ejecuta entre 150 y 400 instancias de AWS EC2 en cualquier momento dado. Sería todo un desafío proveer esa potencia de cómputo a través de escalabilidad vertical.
Bueno, volvamos a los balanceadores de carga. Son la salsa mágica que hace posible escalar horizontalmente. Enrutan las solicitudes entrantes a uno de los muchos servidores de aplicaciones que generalmente son clones/imágenes espejadas entre sí y envían la respuesta del servidor de aplicaciones al cliente. Cualquiera de ellos debe procesar la solicitud de la misma manera, por lo que es solo una cuestión de distribuir las solicitudes en el conjunto de servidores para que ninguno de ellos esté sobrecargado.
Y eso es. Conceptualmente, los balanceadores de carga son bastante sencillos. Bajo la superficie, ciertamente hay complicaciones, pero no es necesario sumergirse en ellas en nuestra versión 101.
3. Servidores de Aplicaciones Web
A alto nivel, los servidores de aplicaciones web son relativamente simples de describir. Ejecutan la lógica comercial central que maneja la solicitud de un usuario y envía de vuelta HTML al navegador del usuario. Para hacer su trabajo, generalmente se comunican con una variedad de infraestructura de back-end, como bases de datos, capas de almacenamiento en caché, colas de jobs, servicios de búsqueda, otros microservicios, colas de datos/logs y más. Como se mencionó anteriormente, normalmente tienes al menos dos, y muchas veces muchos más, conectados a un balanceador de carga para procesar las solicitudes de los usuarios.
Has de saber que las implementaciones de servidor de aplicaciones requieren elegir un lenguaje específico (Node.js, Ruby, PHP, Scala, Java, C#, .NET, etc.) y un framework web MVC para ese lenguaje (Express for Node.js, Ruby on Rails, Play for Scala, Laravel for PHP, etc.). Sin embargo, sumergirse en los detalles de estos lenguajes y marcos está más allá del alcance de este artículo.
4. Servidores de Bases de Datos
Cada aplicación web moderna utiliza una o más bases de datos para almacenar información. Las bases de datos proporcionan formas de definir tus estructuras de datos, insertar datos nuevos, encontrar datos existentes, actualizar o eliminar datos existentes, realizar cálculos en los datos y más. En la mayoría de los casos, los servidores de aplicaciones web se comunican directamente con uno, al igual que los servidores de jobs. Además, cada servicio de back-end puede tener su propia base de datos aislada del resto de la aplicación.
Aunque trato de evitar una inmersión muy profunda en tecnologías particulares para cada componente de la arquitectura, le estaría haciendo un mal servicio sin mencionar el siguiente nivel de detalle para las bases de datos: SQL y NoSQL.
SQL significa «lenguaje de consulta estructurado» (del inglés «structured query language») y fue inventado en la década de 1970 para proporcionar una forma estándar de consultar conjuntos de datos relacionales que fuera accesible para una audiencia amplia. Las bases de datos SQL almacenan datos en tablas que están vinculadas entre sí a través de ID comunes, generalmente números enteros. Veamos un ejemplo simple de almacenamiento de información de dirección histórica para los usuarios. Es posible que tenga dos tablas, users y user_addresses, vinculadas entre sí por el ID del usuario. Ve la imagen a continuación para una versión simplista. Las tablas están vinculadas porque la columna user_id en la tabla user_addresses es clave foránea de la columna ID en la tabla users.
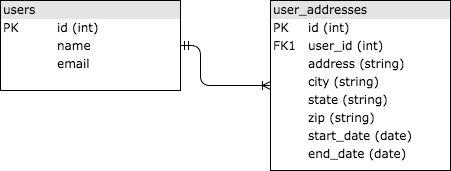
Si no sabes mucho sobre SQL, te recomiendo que sigas un tutorial como el que puedes encontrar en Khan Academy aquí. Es omnipresente en el desarrollo web, por lo que al menos vas a querer conocer los conceptos básicos para diseñar correctamente una aplicación.
NoSQL, que significa exactamente «no SQL», es un nuevo conjunto de tecnologías de bases de datos que ha surgido para manejar la gran cantidad de datos que pueden producir las aplicaciones web a gran escala (la mayoría de las variantes de SQL no se escalan horizontalmente muy bien y solo puede escalar verticalmente a un cierto punto). Si no sabes nada sobre NoSQL, te recomiendo comenzar con algunas introducciones de alto nivel como estas:
También deberías tener en cuenta que, en general, la industria se está alineando en SQL como interfaz incluso para las bases de datos NoSQL, por lo que realmente debería aprender SQL si no lo sabes. Casi no hay forma de evitarlo en estos días.
5. Servicio de Caché
Un servicio de caché proporciona un almacén de datos de clave/valor simple que permite guardar y buscar información en un tiempo cercano a O(1). Por lo general, las aplicaciones aprovechan los servicios de caché para guardar los resultados de cálculos costosos para que sea posible recuperar los resultados de la memoria caché en lugar de volver a calcularlos la próxima vez que se necesiten. Una aplicación puede almacenar en caché los resultados de una consulta de base de datos, llamadas a servicios externos, HTML para una URL determinada y muchos más. Aquí hay algunos ejemplos de aplicaciones del mundo real:
- Google almacena en caché los resultados de búsqueda para consultas de búsqueda comunes como «perro» o «Taylor Swift» en lugar de volver a calcularlas cada vez.
- Facebook almacena en caché gran parte de los datos que ve cuando inicia sesión, como datos de publicaciones, amigos, etc. Lee aquí un artículo detallado sobre la tecnología de almacenamiento en caché de Facebook.
- Storyblocks almacena en caché la salida HTML de la representación de React del lado del servidor, resultados de búsqueda, resultados de escritura anticipada y más.
Las dos tecnologías de servidor de almacenamiento en caché más extendidas son Redis y Memcache.
6. Colas de Jobs y Servidores
La mayoría de las aplicaciones web necesitan hacer un trabajo asíncrono tras bambalinas que no está directamente asociado con la respuesta a la solicitud de un usuario. Por ejemplo, Google necesita rastrear e indexar toda la Internet para devolver los resultados de búsqueda. No hace esto cada vez que busca. En cambio, rastrea la web de forma asincrónica, actualizando los índices de búsqueda en el camino.
Si bien existen diferentes arquitecturas que permiten realizar trabajos asincrónicos, la más ubicua es la que denominaré arquitectura de «cola de trabajos» (job queue). Se compone de dos componentes: una cola de «trabajos» que deben ejecutarse y uno o más servidores de trabajos (a menudo llamados «workers») que ejecutan los trabajos en la cola.
Las colas de trabajos (o «jobs») almacenan una lista de trabajos que deben ejecutarse de forma asincrónica. Las más simples son las colas «primero en entrar, primero en salir» (FIFO), aunque la mayoría de las aplicaciones terminan necesitando algún tipo de sistema de colas priorizadas. Siempre que la aplicación necesite ejecutar un trabajo, ya sea en algún tipo de programación regular o según lo determinado por las acciones del usuario, simplemente agrega el trabajo apropiado a la cola.
Storyblocks, por ejemplo, aprovecha una cola de trabajo para impulsar gran parte del trabajo tras bambalinas requerido para dar soporte a nuestros mercados. Realizamos trabajos para codificar videos y fotos, procesar archivos CSV para etiquetado de metadatos, agregar estadísticas de usuarios, enviar correos electrónicos de restablecimiento de contraseña y más. Comenzamos con una cola FIFO simple, aunque actualizamos a una cola priorizada para garantizar que las operaciones urgentes como el envío de correos electrónicos de restablecimiento de contraseña se completen lo antes posible.
Los servidores de trabajos procesan trabajos. Sondean permanentemente la cola de trabajos para determinar si hay trabajo que hacer y, si lo hay, sacan un trabajo de la cola y lo ejecutan. Las opciones de lenguajes de programación y marcos subyacentes son tan numerosas como para los servidores web, por lo que no profundizaré en este artículo.
7. Servicio de Búsqueda de Texto
Muchas, si no la mayoría de las aplicaciones web admiten algún tipo de función de búsqueda en la que un usuario proporciona una entrada de texto (a menudo llamada «consulta») y la aplicación devuelve los resultados más «relevantes». La tecnología que impulsa esta funcionalidad generalmente se conoce como «búsqueda de texto completo», que aprovecha un índice invertido para buscar rápidamente documentos que contienen las palabras clave de consulta.

Ejemplo que muestra cómo tres títulos de documentos se convierten en un índice invertido para facilitar la búsqueda rápida de una palabra clave específica a los documentos con esa palabra clave en el título. Tenga en cuenta que las palabras comunes como «en», «El», «con», etc. (llamadas palabras de detención), generalmente no se incluyen en un índice invertido.
Si bien es posible realizar una búsqueda de texto completo directamente desde algunas bases de datos (por ejemplo, MySQL admite la búsqueda de texto completo), es típico ejecutar un «servicio de búsqueda» separado que computa y almacena el índice invertido y proporciona una interfaz de consulta. La plataforma de búsqueda de texto completo más popular hoy en día es Elasticsearch, aunque hay otras opciones como Sphinx o Apache Solr.
8. Servicios
Una vez que una aplicación alcanza una cierta escala, es probable que haya ciertos «servicios» diseñados para ejecutarse como aplicaciones separadas. No están expuestos al mundo externo, pero la aplicación y otros servicios interactúan con ellos. Storyblocks, por ejemplo, tiene varios servicios operativos y planificados:
- El servicio de cuentas de usuario almacena datos de usuarios en todos nuestros sitios, lo que nos permite ofrecer fácilmente oportunidades de venta cruzada y crear una experiencia de usuario más unificada.
- El servicio de contenidos almacena metadatos para todo nuestro contenido de video, audio e imagen. También proporciona interfaces para descargar el contenido y ver el historial de descargas.
- El servicio de pago proporciona una interfaz para facturar tarjetas de crédito de clientes.
- El servicio de HTML a PDF proporciona una interfaz simple que acepta HTML y devuelve el documento PDF correspondiente.
9. Datos
Hoy, las empresas viven y mueren en función de lo bien que aprovechan los datos. En la actualidad, casi todas las aplicaciones, una vez que alcanzan cierta escala, aprovechan una tubería de datos para garantizar que los datos se puedan recopilar, almacenar y analizar. Una tubería típica tiene tres etapas principales:
- La aplicación envía datos, generalmente eventos sobre las interacciones del usuario, a la manguera de datos que proporciona una interfaz de transmisión para ingerir y procesar los datos. Muchas veces los datos sin procesar se transforman o aumentan y pasan a otra manguera. AWS Kinesis y Kafka son las dos tecnologías más comunes para este propósito.
- Los datos en bruto, así como los datos finales transformados/aumentados se guardan en el almacenamiento en la nube. AWS Kinesis proporciona una configuración llamada «manguera de bomberos» (firehose) que hace que guardar los datos sin procesar en tu almacenamiento en la nube (S3) sea extremadamente fácil de configurar.
- Los datos transformados/aumentados a menudo se cargan en un almacén de datos para su análisis. Usamos AWS Redshift, al igual que una gran y creciente porción del mundo de las startups, aunque las compañías más grandes a menudo usarán Oracle u otras tecnologías de almacenamiento propietarias. Si los conjuntos de datos son lo suficientemente grandes, es posible que se requiera una tecnología NoSQL MapReduce similar a Hadoop para el análisis.
Otro paso que no se muestra en el diagrama de arquitectura: cargar datos de las bases de datos operativas de la aplicación y los servicios en el almacén de datos. Por ejemplo, en Storyblocks cargamos nuestras VideoBlocks, AudioBlocks, Storyblocks, servicio de cuentas de usuarios y bases de datos de portal de colaboradores en Redshift todas las noches. Esto proporciona a nuestros analistas un conjunto de datos holístico al ubicar los datos comerciales centrales junto con nuestros datos de eventos de interacción con el usuario.
10. Almacenamiento en la Nube
«El almacenamiento en la nube es una forma simple y escalable de almacenar, acceder y compartir datos a través de Internet», según AWS. Puedes usarlo para almacenar y acceder a más o menos cualquier cosa que almacene en un sistema de archivos local con los beneficios de poder interactuar con él a través de una API RESTful a través de HTTP. La oferta de Amazon S3 es, con mucho, el almacenamiento en la nube más popular disponible en la actualidad y en el que confiamos ampliamente aquí en Storyblocks para almacenar nuestros recursos de video, fotos y audio, nuestro CSS y Javascript, nuestros datos de eventos de usuarios y mucho más.
11. CDN
CDN significa «Content Delivery Network» (Red de Entrega de Contenidos) y la tecnología proporciona una forma de entregar servicios como HTML estático, CSS, Javascript e imágenes en la web mucho más rápido que entregarlos desde un único servidor de origen. Funciona mediante la distribución del contenido en muchos servidores «perimetrales» en todo el mundo para que los usuarios terminen descargando activos de los servidores «perimetrales» en lugar del servidor de origen. Por ejemplo, en la imagen a continuación, un usuario en España solicita una página web de un sitio con servidores de origen en Nueva York, pero los activos estáticos de la página se cargan desde un servidor «borde» CDN en Inglaterra, lo que evita requerimientos HTTP lentos a través del Atlántico.
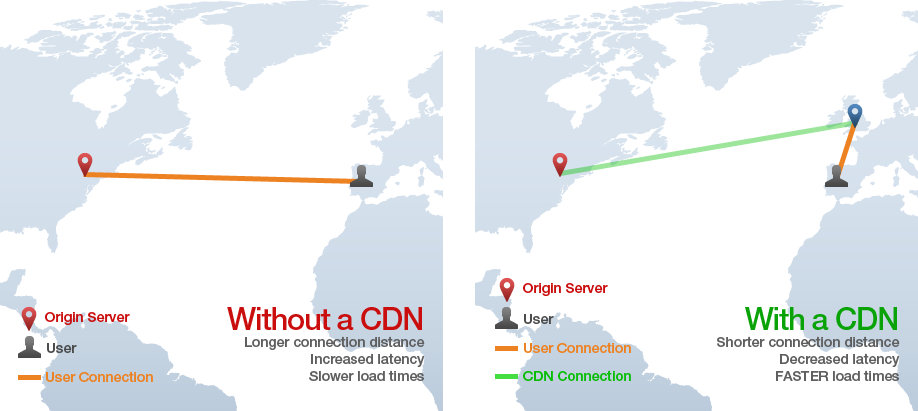
Fuente: https://www.creative-artworks.eu/why-use-a-content-delivery-network-cdn
Mira este artículo para una introducción más completa. En general, una aplicación web siempre debe usar un CDN para servir CSS, Javascript, imágenes, videos y cualquier otro activo. Algunas aplicaciones también pueden aprovechar una CDN para servir páginas HTML estáticas.
Esta es una traducción del artículo de Jonathan Fulton, SVP Product & Engineering en la compañía de venta de medios Storyblocks. Se publicó el 7 de noviembre de 2017 en su blog, donde puedes leer el artículo original aquí.